Popular Keywords





Articles
News

[News] Samsung’s DS Unit Delivers 99.7% of Q2 Profit amid Memory Boom; HBM4 Revenue Reportedly to Triple in Q3
Samsung Electronics delivered another record second quarter, with operating profit jumping 19-fold year over year to KRW 89.5 trillion. While memory’s role as the key earnings driver came as little surprise, the scale of its contribution was striking: the DS division accounted for a 99.7% of Samsu...
News

[News] Mass Production and Capacity Expansion Accelerate, Reshaping the Foundry Landscape in Silicon Photonics
As AI computing power drives data transmission bandwidth demand to double every two years, the physical limits of copper interconnects are becoming increasingly apparent. How can the “traffic congestion” between chips be alleviated? An increasing number of wafer foundries are turning to one answ...
News

[News] Intel Reportedly to Cut 103 Jobs in Mid-August After DCAI Layoff News Emerges
Intel confirmed last week that it would launch a new round of layoffs in its Data Center and AI Group, though the company has yet to disclose the scale. New details have since surfaced, though Intel has not confirmed a direct link between the two. According to the Francisco Chronicle, Intel plans to...
News

[News] Samsung Electro-Mechanics Lifts MLCC Prices 30% Starting Aug. 1; Taiyo Yuden Reportedly Eyes Sept. 1 Hike
Samsung Electro-Mechanics has notified customers of a new round of MLCC price increases. According to TechNews, the price adjustment applies to all MLCC products under Samsung Electro-Mechanics' Markup Business Code, with prices set to increase by 30% from current levels. The new pricing will apply ...
Insights
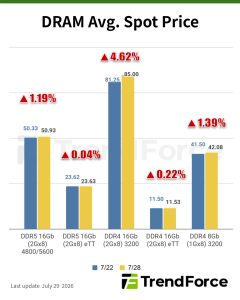
[Insights] Memory Spot Price Update: DRAM Spot Prices Rise Slightly as DDR3, DDR4 and DDR5 Inquiries Pick Up
According to TrendForce’s latest memory spot price trend report, DRAM spot prices edged higher this week as inquiries for DDR3, DDR4, and DDR5 chips remained active. Mainstream DDR4 spot prices rose 1.39% to US$42.08. In NAND Flash, however, the spot market remained subdued amid limited broad-base...
- Page 3
- 1021 page(s)
- 5105 result(s)