NVIDIA Expands Product Portfolio to Address AI Training and Inference, Responding to an ASIC Push from CSPs, Says TrendForce
According to TrendForce’s latest findings on the AI servers, major CSPs are increasing investment in self-developed chips. In response, NVIDIA shifted the focus of GTC 2026 toward deploying AI inference applications across multiple industries, marking a departure from its previous emphasis on cloud-based AI training.
NVIDIA is advancing a diversified product portfolio, which includes GPUs, CPUs, and LPUs, to address both training and inference workloads, while promoting rack-level integrated systems to drive growth across its supply chain ecosystem.
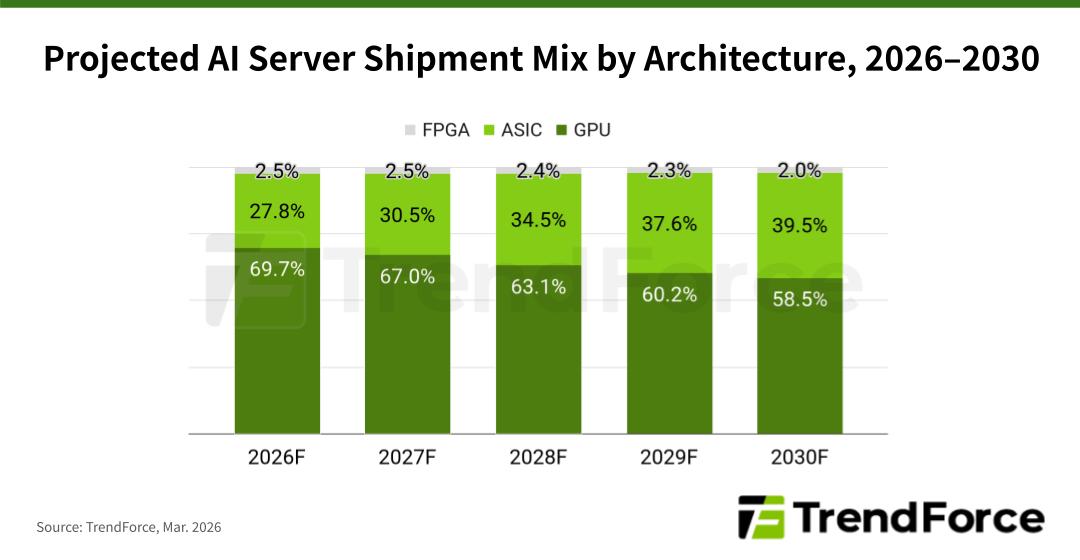
TrendForce reports that as CSPs like Google and Amazon increase their internal chip development, ASIC-based AI servers are forecast to represent 27.8% of all AI server shipments in 2026. This percentage is expected to grow to nearly 40% by 2030.
NVIDIA is promoting rack-scale solutions that integrate CPUs and GPUs, including GB300 and VR200 platforms, with scalability for inference workloads to reinforce its leadership in the AI market. At GTC 2026, the company introduced Vera Rubin, a highly vertically integrated system that combines seven chips and five rack configurations.
Memory vendors are expected to begin supplying HBM4 for Rubin GPUs in 2Q26, enabling NVIDIA to start shipping Rubin chips around 3Q26.
Meanwhile, shipments of NVIDIA’s GB300 and VR200 rack systems are progressing. The GB300 platform replaced the GB200 as the company’s flagship solution in 4Q25, and its shipment share is expected to reach nearly 80% in 2026. The VR200 rack system is projected to begin ramping shipments toward late 3Q26, although the actual timeline will depend on the production schedules of ODMs.
As AI evolves from generative models to agent-based architectures, the decode stage of token generation has become a major bottleneck due to latency and memory bandwidth constraints. NVIDIA is tackling this challenge by integrating technology from the Groq team, introducing the Groq 3 LPU designed specifically for low-latency inference workloads. Each chip integrates 500 MB of SRAM, and a full rack system can provide up to 128 GB of on-chip memory.
However, the memory capacity of LPUs alone cannot accommodate the massive model parameters and KV cache required by systems such as Vera Rubin. NVIDIA therefore introduced “disaggregated inference” at GTC 2026, where the inference pipeline is divided into two stages through an AI factory operating system called Dynamo.
In agent-based AI workloads, the pre-fill and attention stages, which require intensive computation and large KV cache storage, are handled by Vera Rubin systems equipped with high-throughput and large-memory capacity. The decode and token generation stages, which are highly latency-sensitive and bandwidth-limited, are offloaded to LPU racks with expanded memory capacity.
The third-generation Groq LP30 chip, fabricated by Samsung, has entered full-scale production and is expected to begin shipping in 2H26. NVIDIA also plans to introduce a higher-performance LP40 chip in its next-generation Feynman architecture.
For more information on reports and market data from TrendForce’s Department of Semiconductor Research, please click here, or email the Sales Department at SR_MI@trendforce.com
For additional insights from TrendForce analysts on the latest tech industry news, trends, and forecasts, please visit https://www.trendforce.com/news/

