
Crossing AI Memory Wall: Storage Layer Reallocation and HBF Analysis
Last Modified
2026-04-23
Update Frequency
Not
Format
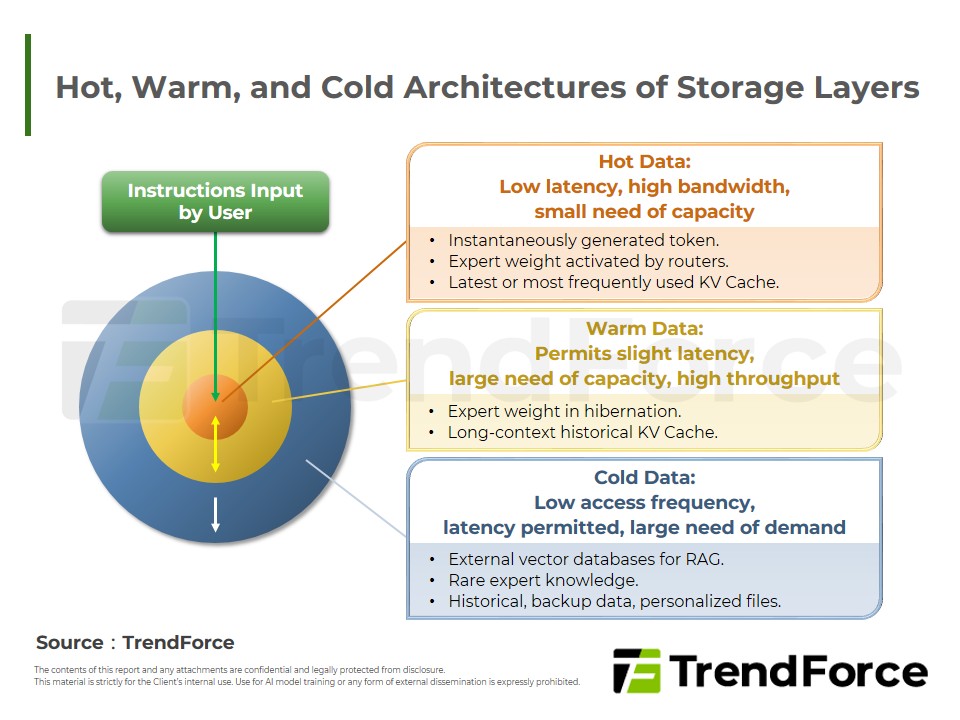
In AI inference, MoE architectures and long-context processing have sharply increased memory-capacity requirements for model weights and KV cache, shifting the bottleneck from insufficient compute to limited memory capacity. As warm data grows rapidly, this will drive a restructuring of the storage hierarchy, where HBM will handle hot data, while HBF will carry warm data to optimize cost–performance. However, commercialization of HBF still needs to overcome challenges in advanced packaging processes and the inherent characteristics of NAND flash.
Key Highlights
- Bottleneck: AI advancements shifted the bottleneck from compute power to memory capacity.
- Hierarchy: Surging warm data demands tiered storage: HBM for hot data and HBF for warm, maximizing cost-efficiency.
- HBF Hurdles: Commercialization requires overcoming advanced packaging and NAND flash limitations.
Table of Contents
- Development Bottlenecks of LLM: Impact on Computing Structures by Transformation of Model Architectures
- Figure 1: Features of MoE
- Figure 2: Deployment Strategies among AI Storage Vendors
- From Computing Bottlenecks to Restructuring of Storage Layers
- Figure 3: Hot, Warm, and Cold Architectures of Storage Layers
- Figure 4: “H³” Architecture
- Table 1: Comparison between HBM and HBF
- TRI’s View
<Total Pages: 13>
Category: Semiconductors
Spotlight Report
-

AI Servers Absorbing LPDRAM Capacity, Signaling Tight Supply as the New Norm

2026/06/05
Selected Topics

PDF
-

Mature Memory Structural Shortage: Price Plateau Era Arrives - 2H26
2026/06/02
Selected Topics
PDF
-

Cascading Shortages in Consumer DRAM: How Capacity Pivots Fuel Legacy Node Adoption
2026/06/17
Selected Topics
PDF
-

SLC NAND Price Surge: Global Capacity Gap & Substitution Wave in 2H 2026
2026/07/06
Selected Topics
PDF
-

AI Wave & DRAM Deficits: 2027 Global DRAM Outlook
2026/07/28
Selected Topics
PDF
-

HBM Market Outlook:HBM Suppliers Seize Pricing Power as AI Demand Fuels Explosive Contract Price Surge
2026/05/27
Selected Topics
PDF
Selected TopicsRelated Reports


Download Report
2,500
Membership
- Selected Topics New
- Selected Topics-182_Crossing Over AI Memory Wall: Reallocation of Storage Layers and Analysis on HBF
Spotlight Report
-
AI Servers Absorbing LPDRAM Capacity, Signaling Tight Supply as the New Norm
2026/06/05
Selected Topics
PDF
-
Mature Memory Structural Shortage: Price Plateau Era Arrives - 2H26
2026/06/02
Selected Topics
PDF
-
Cascading Shortages in Consumer DRAM: How Capacity Pivots Fuel Legacy Node Adoption
2026/06/17
Selected Topics
PDF
-
SLC NAND Price Surge: Global Capacity Gap & Substitution Wave in 2H 2026
2026/07/06
Selected Topics
PDF
-
AI Wave & DRAM Deficits: 2027 Global DRAM Outlook
2026/07/28
Selected Topics
PDF
-
HBM Market Outlook:HBM Suppliers Seize Pricing Power as AI Demand Fuels Explosive Contract Price Surge
2026/05/27
Selected Topics
PDF