Over the past several decades, the semiconductor sector has been driven by Moore’s Law as a key driver, continuously increasing transistor density, improving chip performance, and reducing the cost per unit of computation. As the industry enters the AI era, the Scaling Law has become the new goal. By expanding AI model size, training data volume, and computing resources, developers aim for predictable improvements in model performance. Consequently, industry focus has shifted from the computing capability of individual chips to overall system-level performance.
In this context, limitations in memory bandwidth and data transfer efficiency have become more pronounced, sharply increasing the strategic importance of HBM (High Bandwidth Memory) in recent years. As AI workloads gradually shift from training to inference, CSPs (Cloud Service Providers) are accelerating investment in AI infrastructure and server deployment, further increasing demand for server-grade DRAM such as DDR5.
Consequently, the three major DRAM manufacturers continue to allocate advanced process capacity to high-end server DRAM and HBM, limiting supply for consumer DRAM, fueling a new memory price supercycle, and extending its impact to the consumer electronics market.
Latest 2026 AI Memory Trends: HBM3e Price & DDR5 Shortage
AI is driving a memory supercycle! DDR5 prices are rising while HBM3e orders push the market higher. Despite SRAM challenges, why does HBM maintain its dominant position?
Master the Market TrendsAI Computing Trends Face the "Memory Wall" Challenge
Current mainstream LLMs (Large Language Models) based on the Transformer architecture for deep learning rely heavily on memory access for computational performance. During training, massive datasets, weights, and parameters, along with KV caches during inference, are repeatedly accessed for each token generated. When processor computational growth significantly outpaces memory bandwidth and data transfer capabilities, a large portion of processing time is spent waiting for memory data instead of performing computations. When system performance is limited by data transfer speed, a typical "Memory Wall" problem arises.
In recent years, the computational power of AI chips such as GPUs has grown much faster than memory bandwidth and data transfer efficiency. According to the study "AI and Memory Wall", AI model computing power 3× over two years, whereas memory bandwidth increased by only 1.6× and interconnect bandwidth by about 1.4×. Thus, most computations are limited by memory access and communication efficiency rather than raw processing power.
Figure 1. Scaling of Peak hardware FLOPS, and Memory/Interconnect Bandwidth
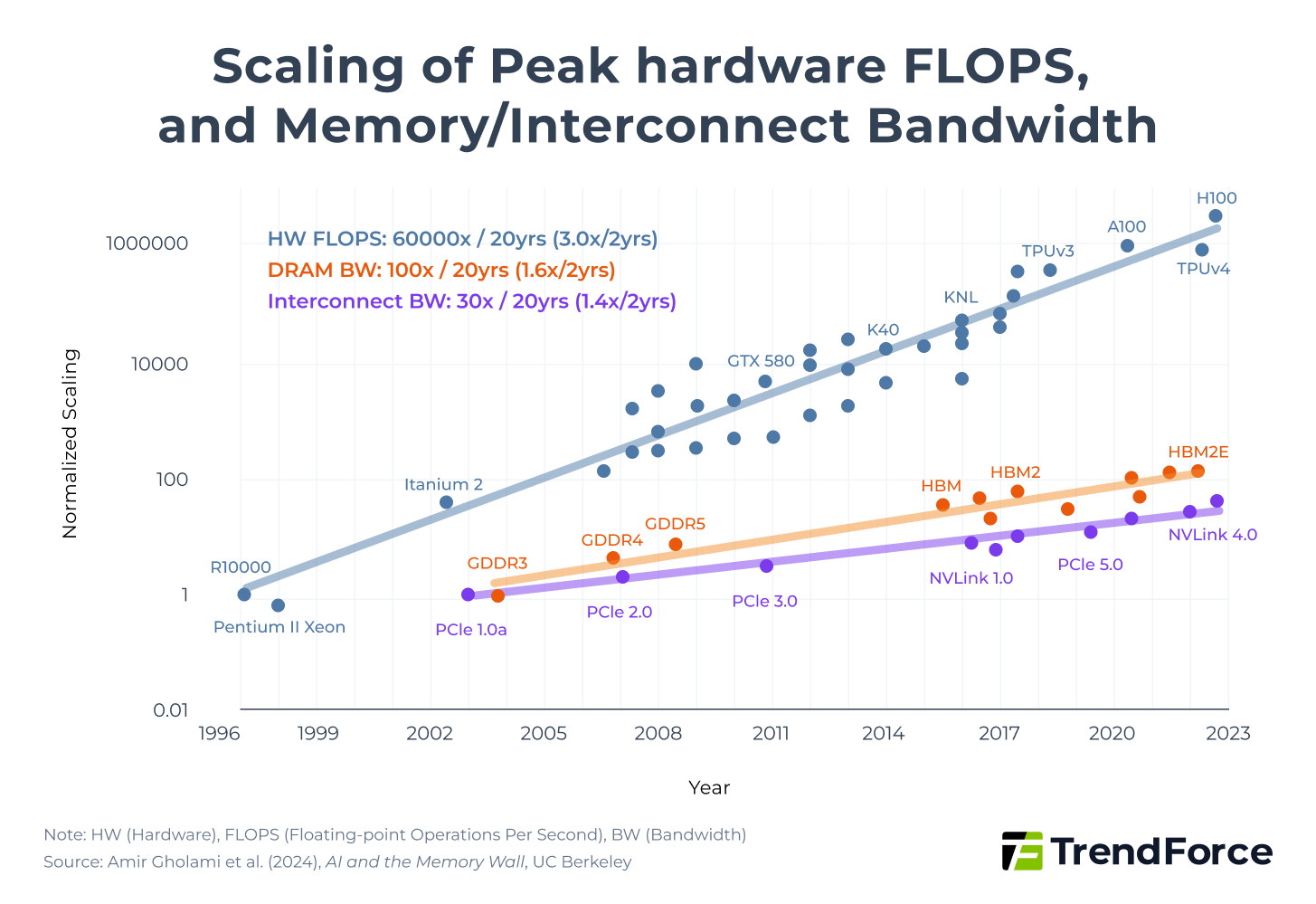
From a theoretical modeling perspective, this structural imbalance can be explained using the Roofline Model. Deep learning models consist largely of matrix multiplications, with total computational workload measured in FLOPs (Floating Point Operations).
The Roofline Model provides a framework to calculate theoretically achievable performance, expressed by the following formula:
$$ P = \min \left( \pi, \beta \times I \right) $$
Figure 2. Roofline Model: Expansion of the Memory-Bound Region under Compute Growth
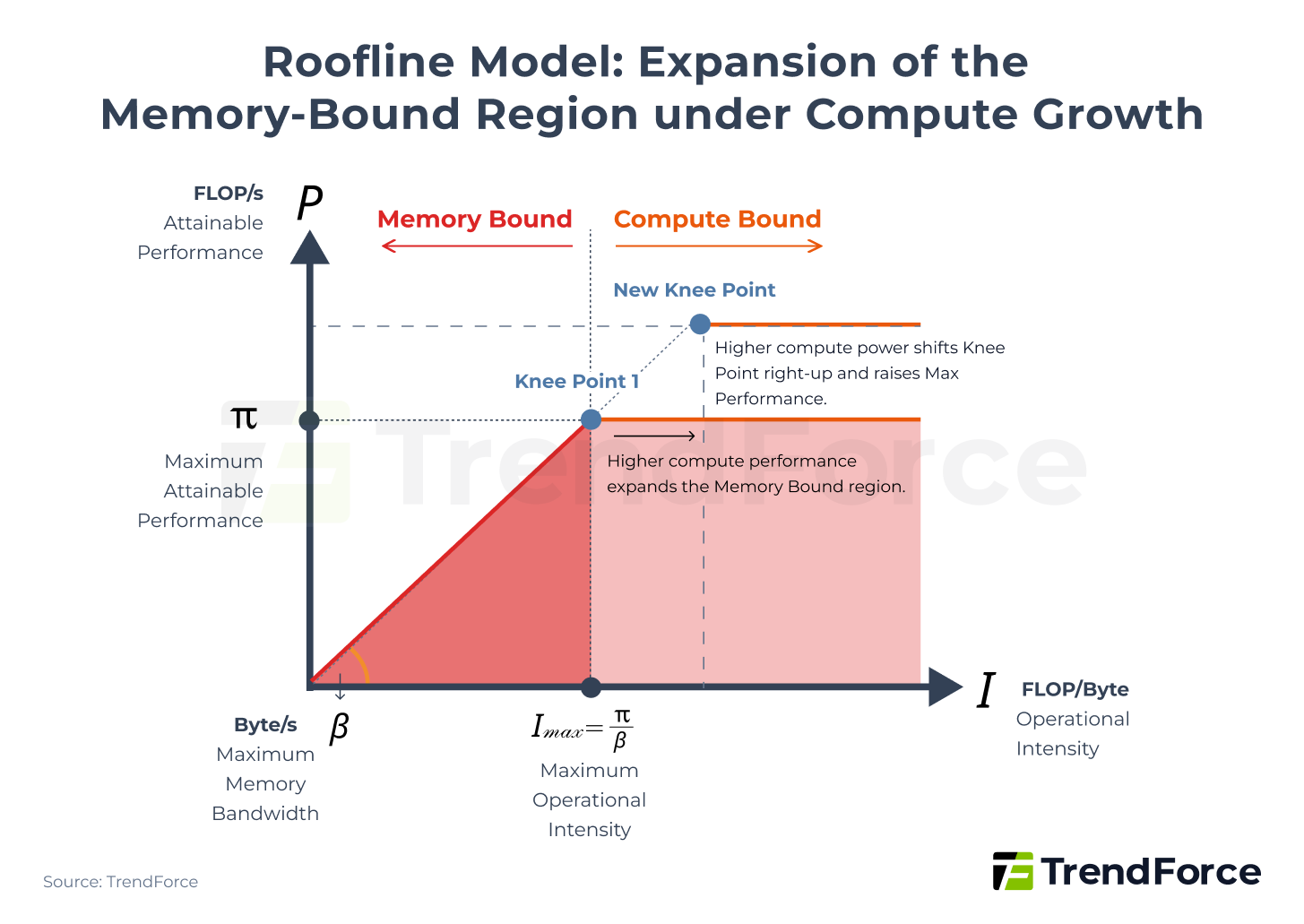
The model indicates that system performance is constrained by Maximum Attainable Performance (π) and Maximum Memory Bandwidth (β), and the Knee Point marks the Minimum Operational Intensity needed to reach Maximum Attainable Performance.
As AI chip compute continues to increase (π rises), if the memory bandwidth slope does not increase correspondingly (β remains constant), the Knee Point shifts upward and to the right, placing a larger portion of the computational workload in the Memory-Bound region. In other words, continuous compute growth intensifies memory limitations on achievable performance. This is why, in the AI era, the focus of AI giants has shifted from simply increasing FLOPs to engaging in a memory arms race.
HBM Becomes the Solution to Accelerate AI Computing
As LLMs continue to scale, even surpassing trillion-level parameters, a single chip can no longer handle full model computation, evolving instead into clusters composed of multiple AI accelerators. The more AI accelerators included in a cluster, the larger the amount of data that must be transferred per second within each AI accelerator and across chips.
In this architecture, data transfer challenges extend further between chips (Scale Out) and even across data center levels (Scale Across). This not only creates a severe Memory Wall bottleneck, but also makes inter-chip bandwidth increasingly critical. Beyond the competition between InfiniBand and Ethernet, HBM has become the optimal memory choice for AI accelerators.
HBM stacks multiple DRAM chips vertically using Through-Silicon Via (TSV) and advanced packaging technology, integrating them with GPUs. Compared with conventional planar DRAM, HBM drastically shortens data transfer paths and features a 1024-bit ultra-wide interface, providing memory bandwidth far exceeding traditional GDDR.
HBM4, expected to enter mass production in 2026, will reach a total bandwidth of 2TB/s, doubling the interface width to 2048-bit while maintaining data transfer rates above 8.0 Gbps. This enables HBM4 to double data throughput without increasing clock speed, further enhancing AI chip performance under high parallelism and data-intensive workloads.
AI Giants’ Spec Arms Race Triggers a Surge in HBM Demand
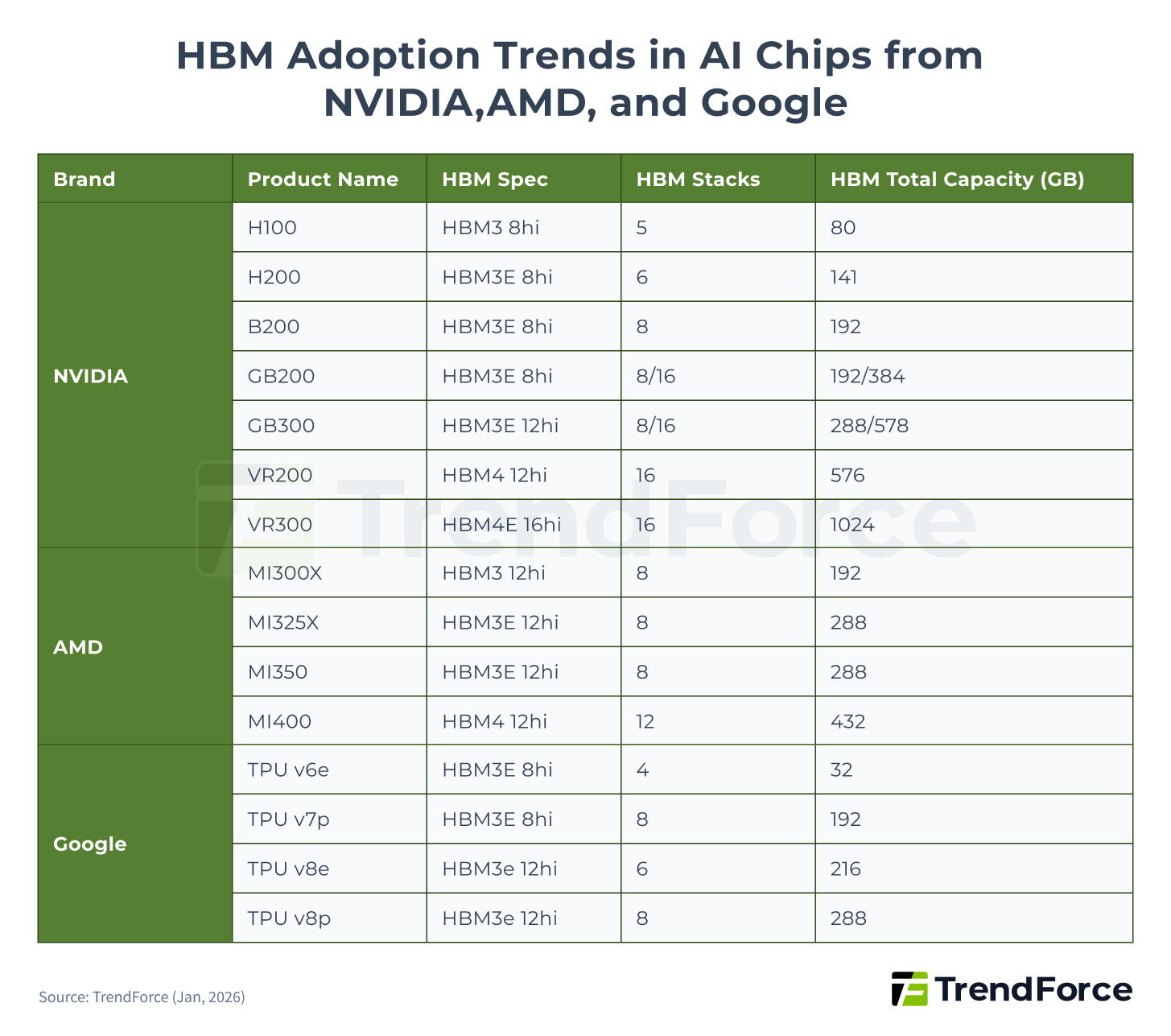
Across successive generations, HBM has advanced in performance, I O count, and bandwidth, emerging as a central pillar in AI accelerator specification upgrades. In recent years, NVIDIA, AMD, and Google have steadily migrated their AI chips toward newer HBM generations, with a clear increase in the number of HBM stacks and total memory capacity per chip, directly driving HBM demand.
Based on TrendForce estimates derived from 2025 AI chip shipments, HBM demand is projected to grow by more than 130% YoY. In 2026, HBM consumption is expected to continue rising, with growth still exceeding 70% YoY, driven primarily by the broader adoption of next generation platforms such as B300, GB300, R100 R200, and VR100 VR200, alongside Google TPU and AWS Trainium accelerating their transition to HBM3e.
Figure 3. HBM Adoption Trends in AI Chips from NVIDIA, AMD, and Google

2026 HBM Outlook: HBM4 Delays and HBM3e Dominance
HBM4 delayed by NVIDIA upgrades! HBM3e rules for now. As Samsung challenges SK hynix with superior tech, who will lead the next wave?
Stay UpdatedAI Inference Rise Drives DDR5 Demand
As AI computing gradually shifts focus from training to inference, it is increasingly applied to end-user scenarios. It is expected that by 2029, AI inference will become the primary driver of demand for AI servers.
Figure 4. AI Server Demand Forecast: Training vs. Inference (2025F–2029F)
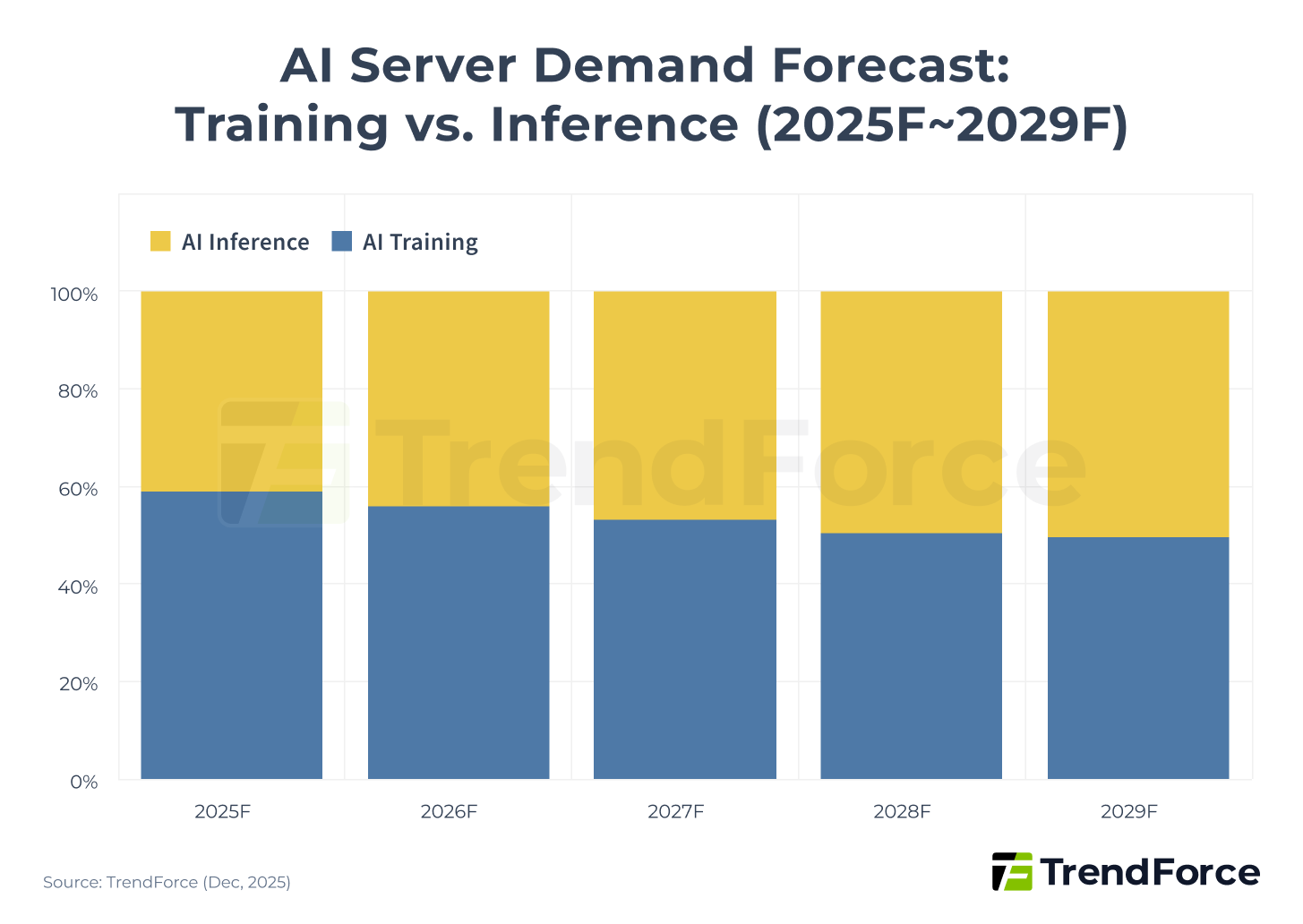
According to a report by McKinsey & Company, by 2028, AI inference is projected to surpass both training and non-AI workloads to become the largest source of power consumption in data centers. This shift will drive comprehensive changes in hardware architecture and energy allocation.
In response to this trend, the industry is re-evaluating hardware configuration strategies across various phases of computation. This has significant implications for hyperscale data center operators in their long-term planning for power supply and network architecture. The goal is to optimize performance-cost balance while effectively reducing total cost of ownership (TCO). This reflects how inference demand is reshaping data center infrastructure across the entire system.
DDR5 Configuration Upgrades and Price Trends under Inference Demand
Differences in memory demand exist between training and inference. During the "training" phase, large datasets are repeatedly processed, which imposes extremely high demands on memory bandwidth. Insufficient bandwidth can cause compute units to remain idle, preventing optimal performance. Therefore, AI accelerators equipped with HBM are commonly used to avoid Memory-Bound bottlenecks.
In contrast, memory demand for "inference" depends on the actual computation stage and can be divided into two phases:
- Prefill: The system processes the complete user input prompts at once, breaking the text into tokens and performing large-scale matrix computations. This stage is compute-intensive but less sensitive to memory bandwidth. Cost-effective DDR or GDDR memory configurations can be used.
- Decode: The model repeatedly accesses weight parameters and KV caches to generate responses token by token. Compute demand decreases at this stage, but memory demand rises significantly. Latency in memory access directly affects the speed of each token generation. Memory configurations with high-bandwidth, high-capacity memory, such as HBM or HBF, remain optimal.
CSPs are expanding general server deployments to meet growing inference demand. DDR5 has emerged as the optimal memory choice, balancing performance and cost. This trend has led North American CSPs, starting in the second half of 2025, to plan 2026 server purchases with a much higher DDR5 deployment, further boosting DDR5 demand and prices.
According to TrendForce analysis, in Q4 2025, contract prices for server DDR5 and HBM3e rapidly converged. HBM3e was originally priced four to five times higher than server DDR5, but the gap is expected to narrow to 1–2 times by the end of 2026.
As standard DRAM profitability gradually increases, some suppliers are shifting capacity toward DDR5, creating more room for HBM3e price growth.
Table 1. HBM vs DDR5: Technology and Application Comparison
| Item | HBM | DDR5 |
|---|---|---|
| Design Architecture | DRAM vertically stacked via TSV and jointly integrated with GPU in a single package | Planar single-chip DRAM, expandable via standard DIMM modules |
| Bus Width | Extremely wide (1024-bit per stack) | Narrower (32-bit x2) |
| Bandwidth | Extremely high (TB/s level) | High (GB/s level) |
| Total Memory Capacity | Lower (capacity fixed due to joint integration with GPU) | High (expandable via DIMM slots) |
| Cost | Very high | Relatively low |
| Power Consumption | Lower | Higher |
| Main Application Scenarios | AI model training and inference (Decode phase), high-performance computing (HPC) | AI model inference (Prefill phase), general servers, and PCs |
BlueField-4 Powers AI Agents: Driving SSD & Inference Demand
AIGC Ignites Demand for AI Inference & Agents! NVIDIA BlueField-4 expands DDR5 memory pools and drives high-performance SSD needs, smashing the memory wall to maximize GPU ROI. Don't miss this critical hardware shift!
Master the Market TrendsMemory Supercycle Hits, Consumer Electronics Take the Brunt
Memory demand from AI and general servers turned the market trend in Q3 2025, causing a supply shortage. The three major DRAM manufacturers prioritized capacity for HBM and high-end server DRAM, but limited fab capacity means supply is unlikely to expand significantly in 2026. At the same time, this squeezed supply for general server and consumer DRAM, driving overall DRAM prices up and signaling the arrival of a new memory supercycle.
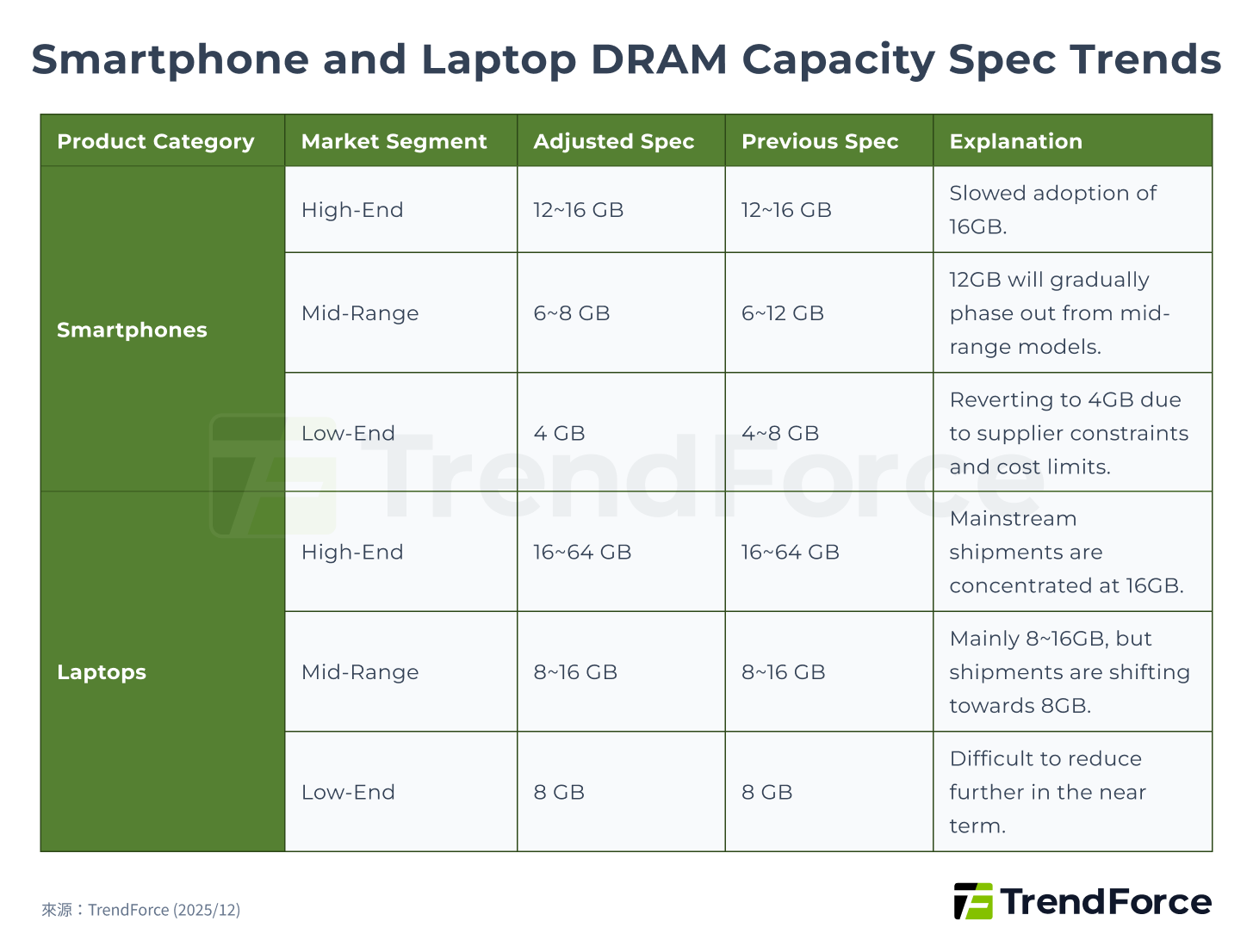
TrendForce expects memory prices to rise sharply again in Q1 2026, and the impact of memory costs on BOM for smartphones, PCs, and other consumer endpoints is growing rapidly. Consumer electronics manufacturers are the hardest hit, directly affecting shipments. Downgrading specifications and delaying upgrades are necessary for smartphone and laptop brands to control costs, with DRAM most affected because it accounts for a large portion of total cost.
Overall, high- and mid-range DRAM capacities are expected to trend toward minimum market standards, slowing the pace of upgrades, while low-end segments in all consumer electronics markets are expected to suffer the most.
Consumer Electronics Profit Crisis, Shipments Weak Across the Board
TrendForce first lowered its global production forecasts for smartphones, laptops, and gaming consoles for 2026 in November 2025. However, as memory prices continued to rise, estimates for all end devices were revised again in late December considering supply chain developments.
The 2026 smartphone production growth was initially expected at 0.1% YoY, then revised down to a 2% decline, and further to 3.5% by late December 2025. In mid-January 2026, it was revised again to a 7% YoY decline. TrendForce further analyzed that even for relatively profitable iPhone models, memory's share of total BOM cost will increase significantly in Q1 2026, forcing Apple to reconsider new device pricing and possibly reduce or cancel planned discounts for older models. For Android brands targeting the mid- to low-end market, memory is one of the key selling points, and its share of BOM cost is already high. As prices surge, low-end smartphones will return to 4GB memory in 2026, prompting brands to adjust pricing or supply cycles to mitigate losses.
The laptop market's 2026 shipments have been revised down from the previously expected annual growth of 1.7% to -2.8%, and further adjusted to -5.4%. Brands with highly integrated supply chains and more flexible pricing, such as Apple and Lenovo, have more flexibility to handle rising memory prices. However, low-end and consumer laptop brands face difficulty passing on costs and are constrained by processor and operating system requirements, making further spec reductions difficult. If memory price increases do not ease in the second quarter, TrendForce forecasts that global laptop shipments in 2026 could further decline by 10.1% YoY.
The 2026 shipment forecast for gaming consoles has been revised down from a previous estimate of a 3.5% YoY decline to 4.4%. For major models like Nintendo Switch 2, Sony PS5, and Microsoft Xbox X, memory costs as a percentage of BOM have risen to 23%–42%, compared with around 15% in the past. Hardware gross margins have therefore been severely compressed. In 2026, the three major manufacturers will struggle to reserve promotional space or follow the previous volume-driven growth strategy, which may further dampen shipment momentum. If memory market conditions do not improve, global gaming console penetration is expected to enter a temporary stagnation phase.
Figure 5. Smartphone and Laptop DRAM Capacity Spec Trends

Memory Capacity Crunch Intensifies, Driving Continued Decline in Inventory
AI pressures the market, creating structural shortages. Supply remains tight even during the PC off-season, with DRAM & NAND prices surging. How long will this seller's market last?
Stay Updated"Breaking the Memory Wall" Arms Race: 2026 Memory Supercycle and Price Surge Outlook
Unlike the 2016–2018 memory supercycle, which was driven by general server demand and lasted about nine quarters, the key driver of this cycle is overcoming the "memory wall." As AI chip computing power continues to grow much faster than memory bandwidth, system performance is increasingly constrained by data transfer efficiency, shifting the industry's competition from raw compute performance to a memory arms race.
This cycle is fueled by both AI and general server demand. To tackle the memory wall bottleneck, the supply product mix has become highly complex, covering HBM, DDR5, enterprise-grade SSDs, and other high-end memory products, which also impacts the availability of standard memory.
With production capacity remaining limited, this memory supercycle is expected to extend into 2026. The market has already become a seller's market, with manufacturers continuing to raise contract prices, manage capacity expansion, and maintain high pricing levels. DRAM prices are projected to rise more than 70% in 2026, and trends of shortage and price surges are expected to persist.

1Q26 Memory Price Forecast
AI Squeeze! The industry faces structural shortages. Even in the PC off-season, supply is critical, and DRAM & NAND prices are surging. How long will this seller's market last?
Master the Market Trends