As AI models grow exponentially in size, data center expansion has shifted from single-system scale-up architectures to scale-out architectures involving tens of thousands of interconnected nodes. The scale-out network market is primarily dominated by two competing technologies:
- InfiniBand: Known as the performance leader and driven by NVIDIA’s subsidiary Mellanox, it leverages native RDMA protocols to deliver extremely low latency—under 2 microseconds—with zero packet loss risk.
- Ethernet: Featuring an open ecosystem and significant cost advantages, it is championed by major players such as Broadcom.
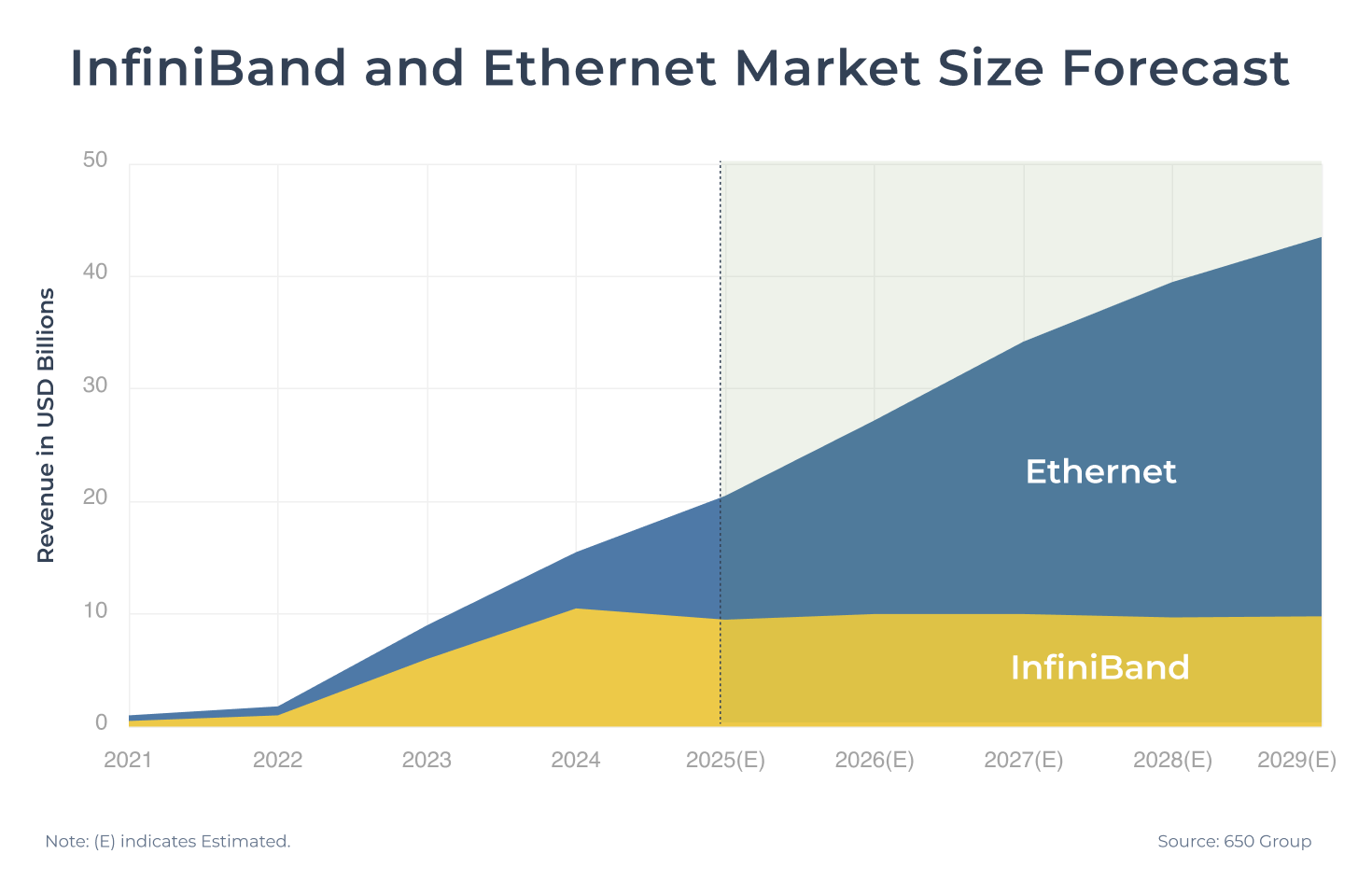
In June 2025, Ethernet launched a strong counterattack as the Ultra Ethernet Consortium (UEC) released UEC 1.0, a specification that reconstructs the network stack to achieve InfiniBand-like performance. With multiple advantages, Ethernet is expected to gradually expand its market share. This technological shift is reshaping the entire competitive landscape of the scale-out market.
Figure 1
2025 Global AI Data Center Interconnect Trends
High-speed optical interconnect and CPO are reshaping AI data centers, defining the architectures and market dynamics of Scale-Up, Scale-Out, and Scale-Across systems.
Get Trend IntelligenceKey Battleground for Scale-Out: InfiniBand Advantages and Ethernet Counterattack
The mainstream InfiniBand architecture for Scale-Out inherently supports Remote Direct Memory Access (RDMA), which operates as follows:
- During data transfer, the DMA controller sends data to a network interface card (RNIC) that supports RDMA.
- The RNIC packages the data and directly transmits it to the receiving RNIC.
Because this process bypasses the CPU, unlike traditional TCP/IP protocols, InfiniBand data transfers can achieve extremely low latency, under 2 μs.
Additionally, InfiniBand features a link-layer Credit-Based Flow Control (CBFC) mechanism, which ensures data is only transmitted when the receiver has available buffer space, guaranteeing zero packet loss.
The native RDMA protocol requires an InfiniBand switch to function. However, InfiniBand switches have long been dominated by NVIDIA's Mellanox, making the ecosystem relatively closed, with higher procurement and maintenance costs; hardware costs are approximately three times those of Ethernet switches.
Table 1. InfiniBand Technology Evolution
| Year | 2011 | 2015 | 2017 | 2021 | 2024 | 2027 | 2030 |
|---|---|---|---|---|---|---|---|
| Data Rate | FDR (Fourteen Data Rate) |
EDR (Enhanced Data Rate) |
HDR (High Data Rate) |
NDR (Next Data Rate) |
XDR (eXtreme Data Rate) |
GDR (E) | LDR (E) |
| Bandwidth/Port (8 Lanes) | 109 Gbps | 200 Gbps | 400 Gbps | 800 Gbps | 1.6 Tbps | 3.2 Tbps | 6.4 Tbps |
| Bandwidth/Port (4 Lanes) | 54.5 Gbps | 100 Gbps | 200 Gbps | 400 Gbps | 800 Gbps | 1.6 Tbps | 3.2 Tbps |
| Bandwidth/Lane | 13.6 Gbps | 25 Gbps | 50 Gbps | 100 Gbps | 200 Gbps | 400 Gbps | 800 Gbps |
| Modulation Technology | NRZ | NRZ | NRZ | PAM4 | PAM4 | PAM6 (E) | PAM6 (E) |
Note: (E) indicates "Estimated".
(Source: TrendForce)
Ethernet has gradually gained traction due to its open ecosystem, multiple vendors, flexible deployment, and lower hardware costs.
To bring RDMA advantages to Ethernet, the IBTA (InfiniBand Trade Association) introduced RDMA over Converged Ethernet (RoCE) in 2010. The initial RoCE v1 only added an Ethernet header at the Link Layer, limiting communication to within a Layer 2 subnet and preventing transmission across routers or different subnets.
To enhance deployment flexibility, IBTA released RoCE v2 in 2014. It replaced the InfiniBand GRH (Global Route Header) in the Layer 3 Network Layer with an IP/UDP header. This change allows RoCE packets to be recognized and forwarded by standard Ethernet switches and routers, enabling transmission across multiple subnets or routers, and greatly improving deployment flexibility. However, RoCE v2 latency remains slightly higher than native RDMA, around 5 μs, and it requires additional features, such as PFC and ECN, to reduce the risk of packet loss.
Figure 2
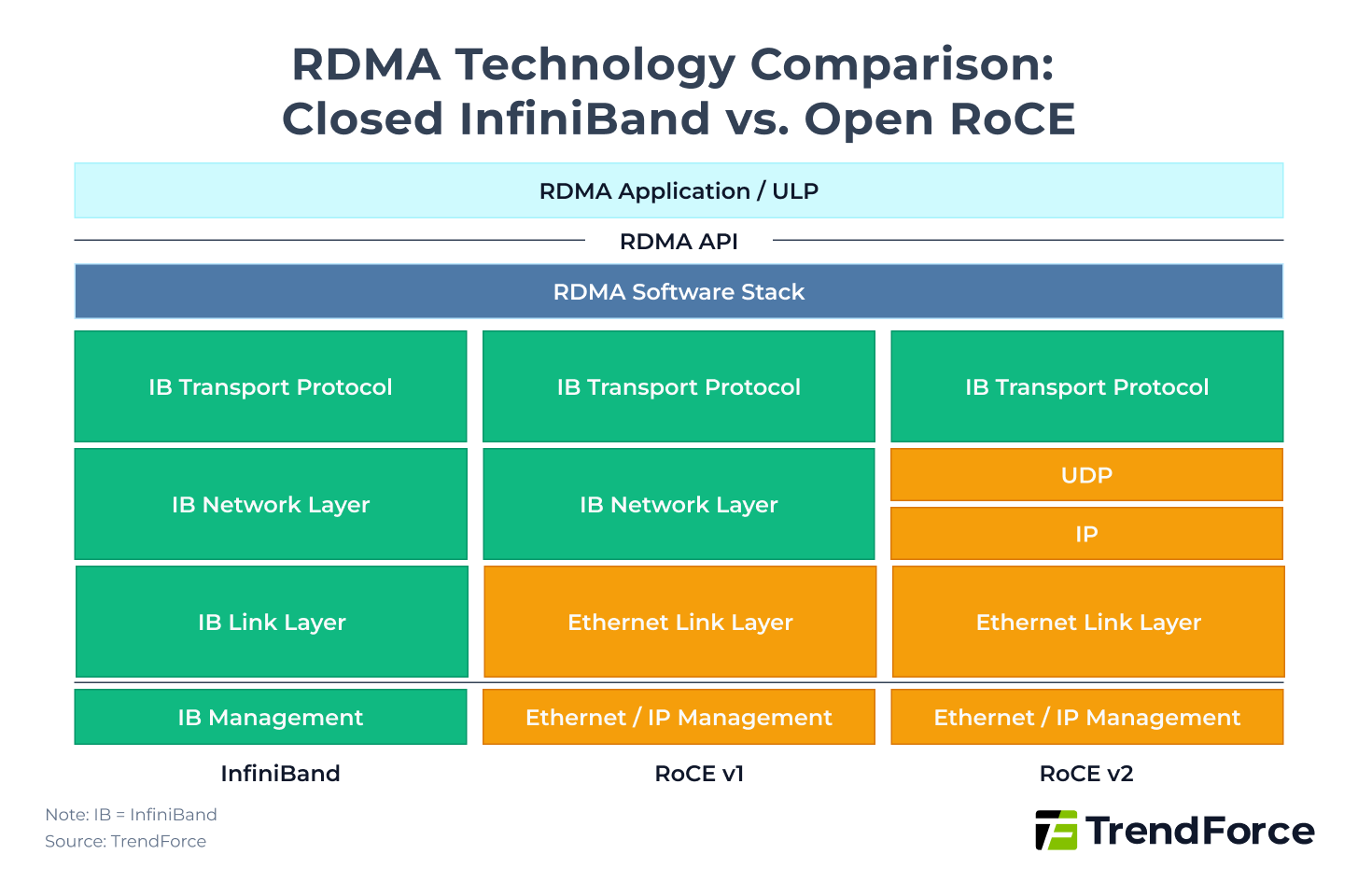
Figure 2 highlights the key comparisons between InfiniBand and open RoCE under RDMA technology:
- InfiniBand uses a closed protocol stack, fully proprietary, achieving the lowest latency.
- RoCE v1 simulates the IB architecture over Ethernet but can only operate within the same Layer 2 subnet.
- RoCE v2 uses the IP network layer, supporting cross-subnet communication and offering the highest compatibility with existing Ethernet data center infrastructures.
Table 2. Ethernet Technology Evolution
| Year | 2016 | 2018 | 2019 | 2021 | 2023 | 2025 | 2027 |
|---|---|---|---|---|---|---|---|
| Single-Chip Total Bandwidth | 3.2 Tbps | 6.4 Tbps | 12.8 Tbps | 25.6 Tbps | 51.2 Tbps | 102.4 Tbps | 204.8 Tbps |
| Single-Chip Port Count | 32 | 64 | 64 | 64 | 64 | 64 | 64 |
| Bandwidth/Port | 100 Gbps | 100 Gbps | 200 Gbps | 400 Gbps | 800 Gbps | 1.6 Tbps | 3.2 Tbps |
| Lane Count/Port | 4 | 4 | 4 | 4 | 8 | 8 | 8 |
| Bandwidth/Lane | 25 Gbps | 25 Gbps | 50 Gbps | 100 Gbps | 100 Gbps | 200 Gbps | 400 Gbps |
| Modulation | NRZ | NRZ | NRZ | PAM4 | PAM4 | PAM4 | PAM6 (E) |
Note: (E) indicates "Estimated".
(Source: TrendForce)
In summary, InfiniBand offers native advantages such as extremely low latency and zero packet loss, which is why it remains widely adopted in today’s AI data centers; however, it has higher hardware and maintenance costs and limited vendor options. In contrast, using RoCE v2 over Ethernet does not achieve the same performance as InfiniBand, but it provides an open ecosystem and lower hardware and maintenance costs, prompting a gradual shift toward Ethernet architectures.
Table 3. Key Technology Comparison of AI Data Center Networks: InfiniBand vs. Ethernet
| Protocol | InfiniBand (RDMA) | Ethernet (RoCE v2) |
|---|---|---|
| Latency | <2 μs | <5 μs |
| Current Mainstream Bandwidth/Port | 800 Gbps | 800 Gbps |
| Lossless Mechanism | Credit-Based Flow Control (CBFC) | Ethernet Flow Control (802.3x), PFC, ECN |
| Ecosystem | Closed (NVIDIA) | Open |
| Hardware Cost | High (1x) | Low (1/3) |
(Source: TrendForce)
Currently, AI data center demand expansion, combined with cost and ecosystem considerations, has led NVIDIA to enter the Ethernet market. NVIDIA currently offers, besides its own InfiniBand Switch Quantum series, Ethernet products under the Spectrum series.
This year, the Quantum-X800 can provide 800 Gbps/Port × 144 Ports, totaling 115.2 Tbps; Spectrum-X800 can provide 800 Gbps/Port × 64 Ports, totaling 51.2 Tbps. The CPO (Co-Packaged Optics) versions of Quantum-X800 and Spectrum-X800 are expected in 2H25 and 2H26, respectively.
Although Spectrum is priced higher than other vendors’ Ethernet switches, NVIDIA’s advantage lies in deep integration with its hardware and software, for example, pairing with the BlueField-3 DPU and DOCA 2.0 platform to achieve high-efficiency adaptive routing.
Switch IC Cost and CPO Deployment Race: Ethernet Leads, InfiniBand Follows
In the Ethernet domain, Broadcom remains the technological leader in Ethernet Switches. Its Tomahawk series of Switch ICs follows the principle of “doubling total bandwidth every two years.” By 2025, Broadcom launched the Tomahawk 6, the world’s highest total bandwidth Switch IC, with a total bandwidth of 102.4 Tbps, supporting 1.6 Tbps/Port × 64 Ports. Additionally, Tomahawk 6 also supports the ultra UEC 1.0 protocol, enabling features such as multipath packet spraying, LLR, and CBFC, further reducing latency and packet loss risks.
Broadcom also leads in CPO technology. Since 2022, it has released the CPO version of Tomahawk 4 Humboldt, followed by Tomahawk 5 Bailly in 2024, and continues with Tomahawk 6 Davisson in 2025, consolidating its leading position in Ethernet hardware integration.
Table 4. Comparison of Scale-Out Switch ICs: Broadcom, NVIDIA, Marvell, Cisco
| Vendor | Broadcom | NVIDIA | Marvell | Cisco | |||||
|---|---|---|---|---|---|---|---|---|---|
| Product | Tomahawk 5 | Tomahawk 6 | Tomahawk 6 (CPO) | Quantum-3 | Quantum-3 (CPO) | Spectrum-4 | Spectrum-4 (CPO) | Teralynx 10 | Cisco Silicon One G200 |
| Release Year | 2023 | 2025 | 2025 | 2024 | 2025 | 2024 | 2026 | 2024 | 2023 |
| Process Node | N5 | N3 | N3 | N4 | N4 | N4 | N4 | N5 | N5 |
| Single-Chip Bandwidth | 51.2 Tbps | 102.4 Tbps | 102.4 Tbps | 28.8 Tbps | 28.8 Tbps | 51.2 Tbps | 102.4 Tbps | 51.2 Tbps | 51.2 Tbps |
(Source: TrendForce)
Compared to Broadcom, which first launched the 102.4 Tbps Tomahawk 6 this year, NVIDIA is expected to release the 102.4 Tbps Spectrum-X1600 only in the second half of 2026, leaving its technology roughly a year behind Broadcom.
Regarding CPO, NVIDIA is also expected to launch the CPO version of the 102.4 Tbps Spectrum-X Photonics in the second half of 2026, aiming to catch up with Broadcom.
Table 5. NVIDIA Scale-Out Network Development Roadmap
| Time | 1H25 | 2H25 | 2H26 | 2H27 | 2028 |
|---|---|---|---|---|---|
| Platform | Blackwell | Blackwell Ultra | Rubin | Rubin Ultra | Feynman |
| InfiniBand Switch | |||||
| Switch | Quantum-2 | Quantum-X800 | Quantum-X1600 | Quantum-X3200 | |
| Total Bandwidth | 51.2 Tbps | 115.2 Tbps | 230.4 Tbps | - | |
| Bandwidth/Port | 400 Gbps | 800 Gbps | 1.6 Tbps | 3.2 Tbps | |
| Ethernet Switch | |||||
| Switch | Spectrum-X800 | Spectrum-X1600 | Spectrum-X3200 | ||
| Total Bandwidth | 51.2 Tbps | 102.4 Tbps | 204.8 Tbps | ||
| Bandwidth/Port | 800 Gbps | 1.6 Tbps | 3.2 Tbps | ||
| Network Interface Card (NIC) | |||||
| SuperNIC | ConnectX-8 | ConnectX-9 | ConnectX-10 | ||
| Bandwidth/Port | 800 Gbps | 1.6 Tbps | 3.2 Tbps | ||
| Bandwidth/Lane | 200 Gbps | 200 Gbps | 400 Gbps | ||
| PCIe Spec | PCIe 6.0 (48 lanes) | PCIe 7.0 (48 lanes) | PCIe 8.0 | ||
(Source: TrendForce)
In addition to the Broadcom and NVIDIA camps, other vendors have also joined the competition. Marvell launched the Teralynx 10 with a total bandwidth of 51.2 Tbps in 2023, and Cisco also released the Cisco Silicon One G200 series with a total bandwidth of 51.2 Tbps in 2023, along with their CPO prototypes.
Electrical Communication Hits Its Limits, Optical Integration Takes Center Stage
Traditional data transmission has primarily relied on copper-based electrical communication. However, as transmission distance requirements increase, optical communication via fiber is gradually showing advantages in Scale-Out scenarios. Compared with electrical communication, optical communication features low loss, high bandwidth, resistance to electromagnetic interference, and long-distance transmission, as shown in Table 6.
Table 6. Comparison of Electrical and Optical Communication Architectures
| Technology | Electrical Communication | Optical Communication |
|---|---|---|
| Medium | Copper | Fiber |
| Main Transmission Rate | 56–112 Gbps | 200 Gbps |
| Interconnect Distance | ≤100 m (distance affected by transmission speed) | MMF (SR): 50–100 m SMF (DR/FR): 500 m–2 km SMF (LR/ER/ZR): 10–80+ km |
| Power Consumption | High at high frequency | High for components, but total power can be reduced via packaging integration |
| Stability | Susceptible to electromagnetic interference | Immune to electromagnetic interference |
| Cost | Lowest cost and simple connections for short distance | Higher initial cost, but better distance/density scalability |
Source: TrendForce
Currently, optical communications mainly use pluggable Optic Transceivers for electro-optical signal conversion. Transmission speeds have reached 200 Gbps per lane, with total bandwidth up to 1.6 Tbps (8 × 200 Gbps).
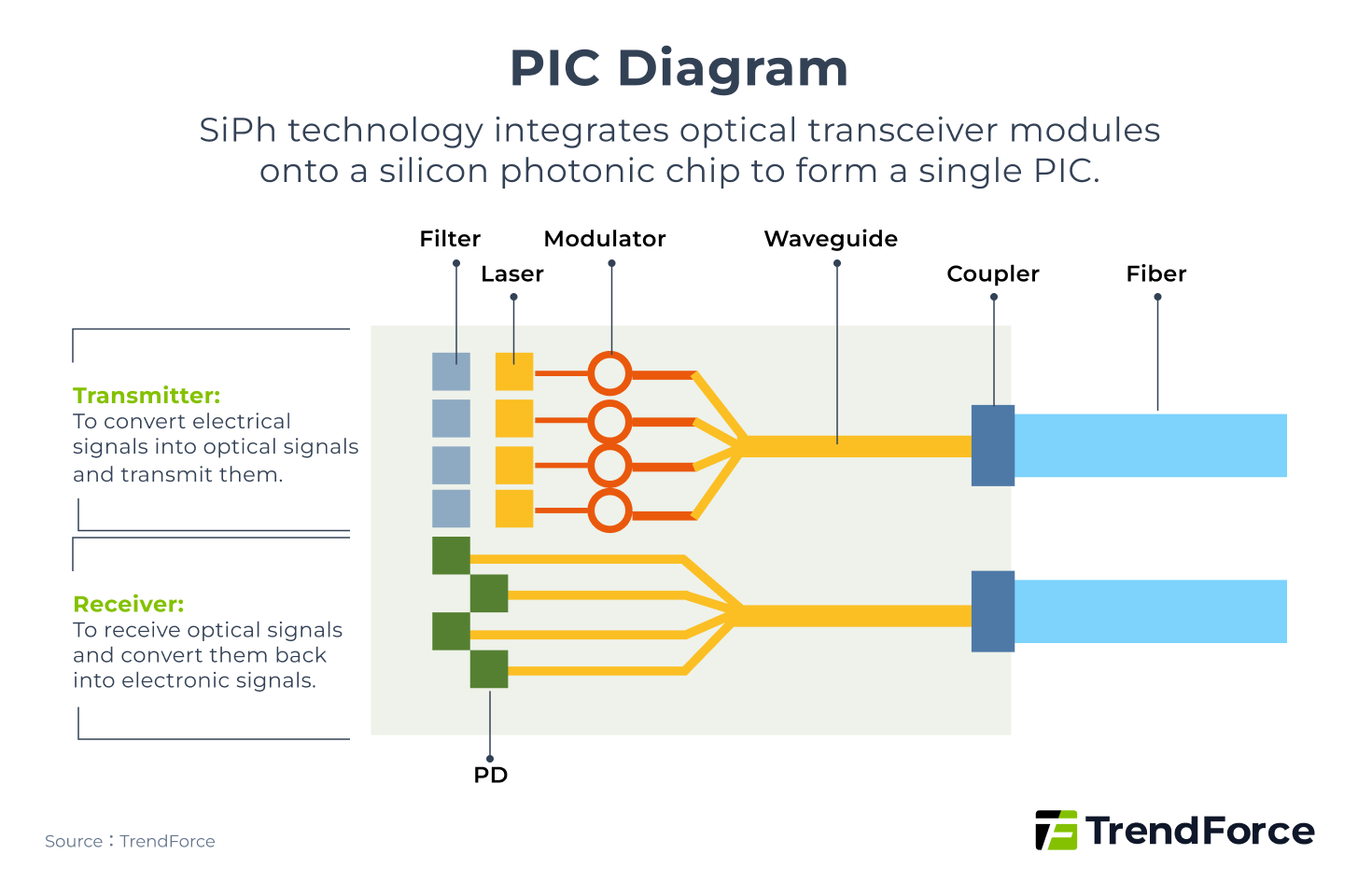
As speeds increase, power consumption rises and signal loss on the circuit board becomes more pronounced. Silicon Photonics (SiPh) technology was developed specifically to address these issues.
Silicon Photonics integrates miniaturized transceiver components into a silicon chip to form a Photonic Integrated Circuit (PIC) as shown below. The PIC is further packaged within the chip, shortening electrical distances and replacing them with optical paths. This packaging method is known as Co-Packaged Optics (CPO).
Figure 3
The broader concept of CPO is shown in Figure 4, encompassing multiple packaging forms, including OBO (On-Board Optics), CPO, and OIO (Optical I/O).
Figure 4
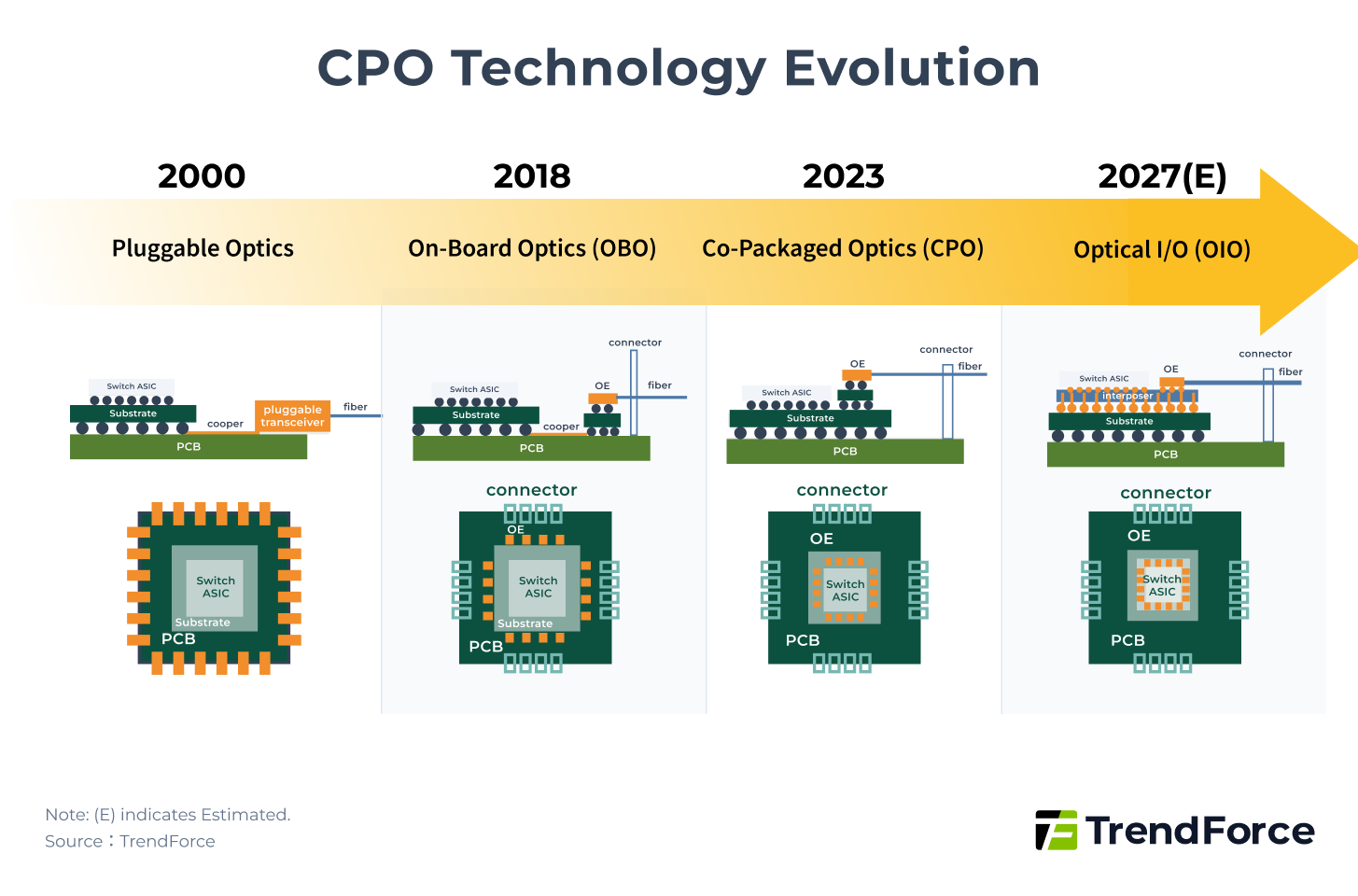
Figure 4 illustrates that the packaging of the Optical Engine (OE) gradually moves closer to the main ASIC. The evolution details are as follows:
- OBO: Packages the OE on the PCB, which is less commonly used today.
- Narrow CPO: Packages the OE on the substrate, which is the current mainstream solution. Compared to pluggable modules, power consumption is reduced to <0.5× (~5 pJ/bit), and latency is reduced to <0.1× (~10 ns).
- OIO: Packages the OE on the interposer, representing the future direction. Compared to pluggable modules, power consumption is reduced to <0.1× (<1 pJ/bit), and latency is reduced to <0.05× (~5 ns).
However, CPO still faces technical challenges such as thermal management, bonding, and coupling. As optical communications approach their limits, breakthroughs in CPO and Silicon Photonics will determine the next battleground for Scale-Out networks.
Global AI Server Trend for 2025: CSPs Expediting Investment and In-House ASICs
Who is leading the next wave of AI infrastructure investment? Cloud giants are ramping up capital expenditure, with full-rack GPUs, custom chips, and liquid cooling systems as the core battlegrounds. Discover the investment strategies of the next-generation AI data centers.
Get Trend IntelligenceEthernet Camp Assembles: UEC Promotes UEC 1.0 Standard
As previously mentioned, InfiniBand's extremely low latency allowed it to capture a significant market share during the early stages of generative AI development. However, as one of the mainstream high-performance network ecosystems, Ethernet also aims to achieve very low latency. In August 2023, the Ultra Ethernet Consortium (UEC) was established, with initial members including AMD, Arista, Broadcom, Cisco, Eviden, HPE, Intel, Meta, and Microsoft.
Compared with the NVIDIA-led InfiniBand ecosystem, UEC emphasizes open standards and interoperability to avoid dependency on a single vendor.
In June 2025, UEC released UEC 1.0, which is not merely an improvement based on RoCE v2 but a complete reconstruction across all layers, including Software, Transport, Network, Link, and Physical.
Figure 5
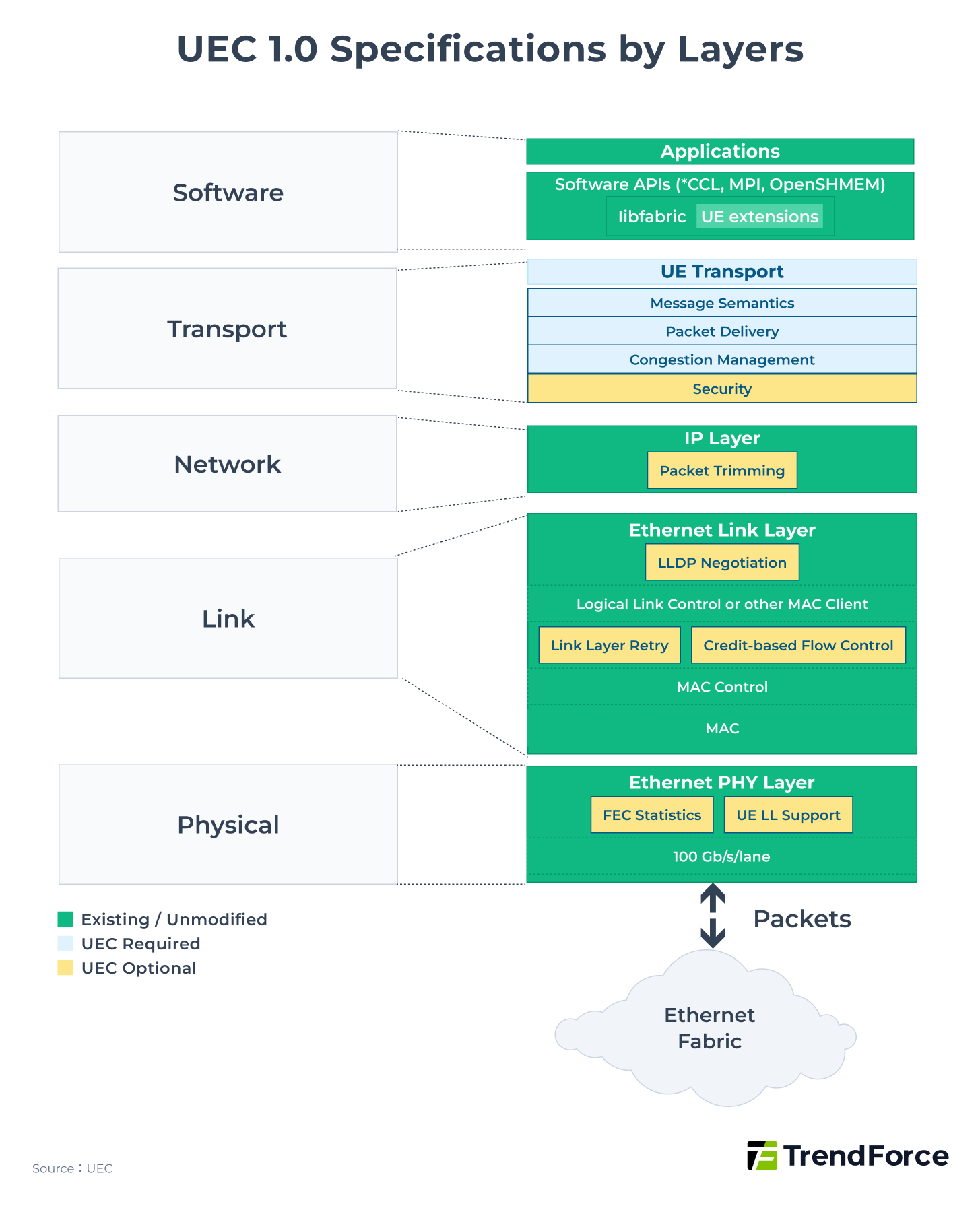
A key modification for reducing latency is the addition of the Packet Delivery Sublayer (PDS) function at the Transport layer. Its main features include:
- Using multipath transmission, where multiple equidistant and equally fast paths (Rails/Lanes) exist between endpoints.
- The NIC distributes packets across all lanes using an entropy value, allowing parallel transmission to achieve greater bandwidth.
This multilayer structure can accelerate network recovery, such as quickly replacing lost packets to ensure smooth traffic, approximating InfiniBand's adaptive routing.
On the other hand, to reduce the risk of packet loss, UEC 1.0 introduces two main changes:
- An optional Link Layer Retry (LLR) function at the Link Layer, which allows a local link to quickly request retransmission when a packet is lost, reducing reliance on Priority Flow Control (PFC) mechanisms.
- An optional Credit-Based Flow Control (CBFC) function at the Link Layer, where the sender must obtain credits from the receiver before transmitting data. The receiver returns new credits after processing and freeing buffer space, achieving flow control with no packet loss risk, similar to InfiniBand’s CBFC.
China’s Scale-Out: Harmonizing Standards and Self-Developed Technology
China’s AI infrastructure scale-out architectures are developing along the principles of autonomy and international compatibility. While adhering to international Ethernet standards, major domestic companies are actively investing in proprietary architectures, gradually forming a scale-out system with local characteristics.
Alibaba, Baidu, Huawei, and Tencent, among other major technology companies, have chosen to join UEC to jointly advance the development of UEC standards. In addition to participating in standardization, Chinese companies are also independently developing proprietary scale-out architectures, generally targeting low latency and zero packet loss, directly benchmarking against InfiniBand.
Table 7. Comparison of China’s Scale-Out and UEC Architectures
| Protocol | UEC 1.0 | GSE 2.0 (China Mobile) | HPN 7.0 (Alibaba Cloud) | UB 1.0 (Huawei) |
|---|---|---|---|---|
| Latency | <2us | <2us | <2us | <2us |
| Main Bandwidth | 800 Gbps | 800 Gbps | 400 Gbps | 400 Gbps |
| Packet Loss Prevention Mechanism | Link Layer Retry (LLR), Credit-Based Flow Control (CBFC) | DGSQ Flow Control | Solar-RDMA, Dual-Plane Traffic Distribution | Link Layer Retry (LLR) |
| Ecosystem | Open | Open | Open | Closed |
Source: TrendForce
The specific details of these proprietary technology architectures are as follows:
- China Mobile: General Scheduling Ethernet (GSE)
China Mobile introduced GSE ahead of the UEC architecture in May 2023. It is divided into two phases:- GSE 1.0 optimizes the existing RoCE network through port-level load balancing and endpoint-network congestion awareness, improving data transmission stability and overall performance while reducing computing waste.
- GSE 2.0 is a complete network reconstruction, reestablishing protocols from the control, transport, to computing layers. It implements Multipath Spraying and traffic control mechanisms (DGSQ) to allocate traffic more efficiently, further reducing latency and packet loss to meet the high-performance demands of future AI computing centers.
- Alibaba Cloud: High-Performance Network (HPN)
Alibaba Cloud’s HPN 7.0 architecture uses a “dual uplink + multi-lane + dual-plane” design. Dual uplinks improve network performance, multi-lane enables parallel packet transmission, and dual-plane strengthens stability. The next-generation HPN 8.0 plans to adopt fully proprietary hardware, such as a 102.4 Tbps Switch IC achieving 800 Gbps bandwidth, benchmarking against international solutions. - Huawei: UB-Mesh Interconnect Architecture
Huawei deploys the proprietary UB-Mesh architecture on the Ascend NPU platform, using a multi-dimensional nD-Full Mesh topology. It supports lateral Scale-Up and vertical Scale-Out. When expanded to three dimensions or more, it reaches the Scale-Out level, capable of supporting ultra-large AI training clusters.
China’s proprietary scale-out architectures continue to develop, expected to provide greater growth opportunities for local companies. With the participation of firms such as ZTE Xuchuang and Guangxun Technology, domestic optical modules and silicon photonics technologies are expected to form a complete industry chain, promoting a uniquely Chinese path in AI infrastructure networking.

2025 Global and China AI Data Centers: Deployment and Outlook
U.S. CSPs scale globally and invest more at home, while Chinese CSPs expand with self-developed chips, but both prioritize energy stability going forward.
Get Trend IntelligenceNext-Gen AI Data Centers: Tech Transformation and Opportunities
For a long time, NVIDIA’s InfiniBand has dominated the Scale-Out market in AI data centers due to its ultra-low latency (under 2 μs) and zero packet loss. However, with the release of the UEC 1.0 standard in June 2025, Ethernet networks are striving to match InfiniBand’s low latency and high stability, gradually regaining market competitiveness. At the same time, Broadcom’s consistent development cycle, doubling Switch IC bandwidth every two years, continues to advance Ethernet hardware capabilities.
As transmission rates reach 1.6 Tbps or higher, the power consumption and latency of traditional pluggable optical modules have become bottlenecks, making Co-Packaged Optics (CPO) technology increasingly standard in high-performance networks. CPO integrates optical transceivers directly onto the switch chip substrate, significantly reducing power and latency. Broadcom has led in CPO technology, launching multiple generations of CPO-based switches since 2022. NVIDIA is also scheduled to release InfiniBand CPO products in the second half of 2025, signaling that CPO will gradually become mainstream in network architecture.
With the maturation of Ethernet and CPO technologies, AI data center networks are moving fully toward high-speed optical communications, creating new growth opportunities for optical transceiver modules and upstream supply chains, including silicon photonics chips, laser sources, and optical fiber modules.
In Scale-Out architectures, NVIDIA is expected to continue leading the traditional InfiniBand market. In the Ethernet domain, Broadcom is projected to maintain a major market share through its leading high-bandwidth Switch ICs, CPO technology, and the implementation of UEC standards.
In August 2025, NVIDIA and Broadcom simultaneously introduced the concept of Scale-Across, aiming to extend connectivity across multiple data centers. This approach will enable larger-scale GPU interconnects and longer-distance transmission, driving a new paradigm in high-performance network and data center architecture.
ASIC Set to Outpace GPU? NVIDIA’s Scale-Up and Beyond
ASIC growth may outpace GPU in 2026, putting NVIDIA under pressure. The battle has moved from chip performance to interconnects, switches, software, and ecosystem.
Unveiling NVIDIA AI Strategy