
TurboQuant Reshapes AI Inference: Memory Demand Expansion Outlook
Last Modified
2026-03-27
Update Frequency
Aperiodically
Format
TurboQuant breaks language model memory bottlenecks via lossless dimensional compression, drastically boosting efficiency. Plummeting costs spark massive long-sequence application demand, comprehensively driving structural growth and specification upgrades for high-bandwidth, main, and flash memory across cloud and edge platforms.
Key Highlights
- Technological Breakthrough: Compresses attention vectors via dimensionality reduction without retraining, maintaining accuracy while vastly saving memory and accelerating inference.
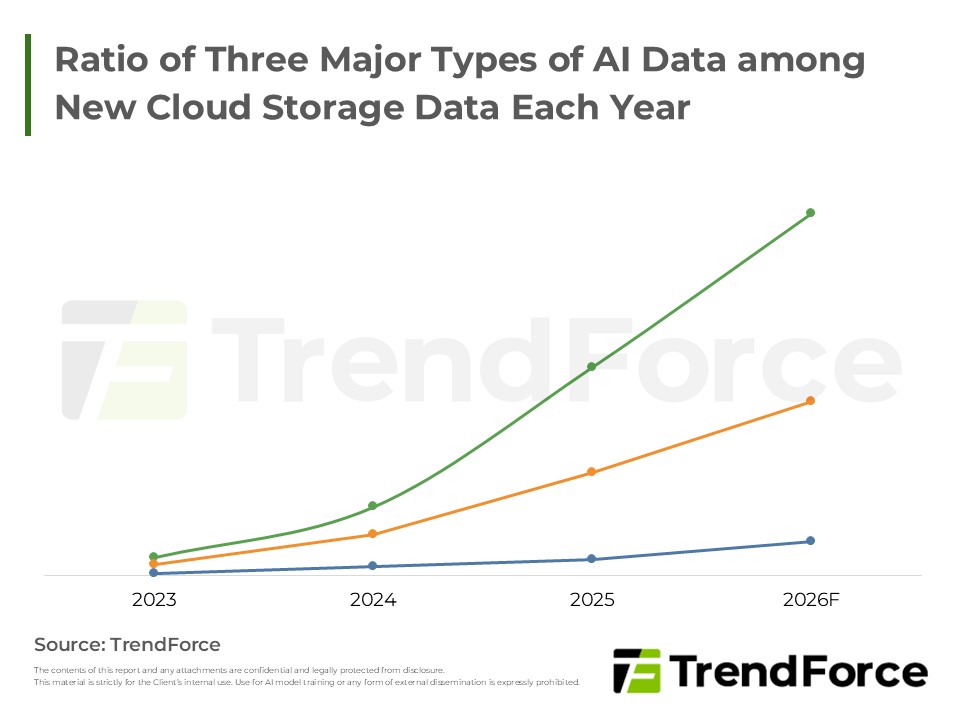
- Market Reshaping: In line with the Jevons Paradox, the rapid reduction in inference costs is likely to drive substantial demand for long-context and multi-agent architectures, further accelerating the migration of AI workloads to the edge.
- Co-design Evolution: Surpasses traditional low-bit quantization by altering data representation, paving the way for future hardware-software integration in computational chips.
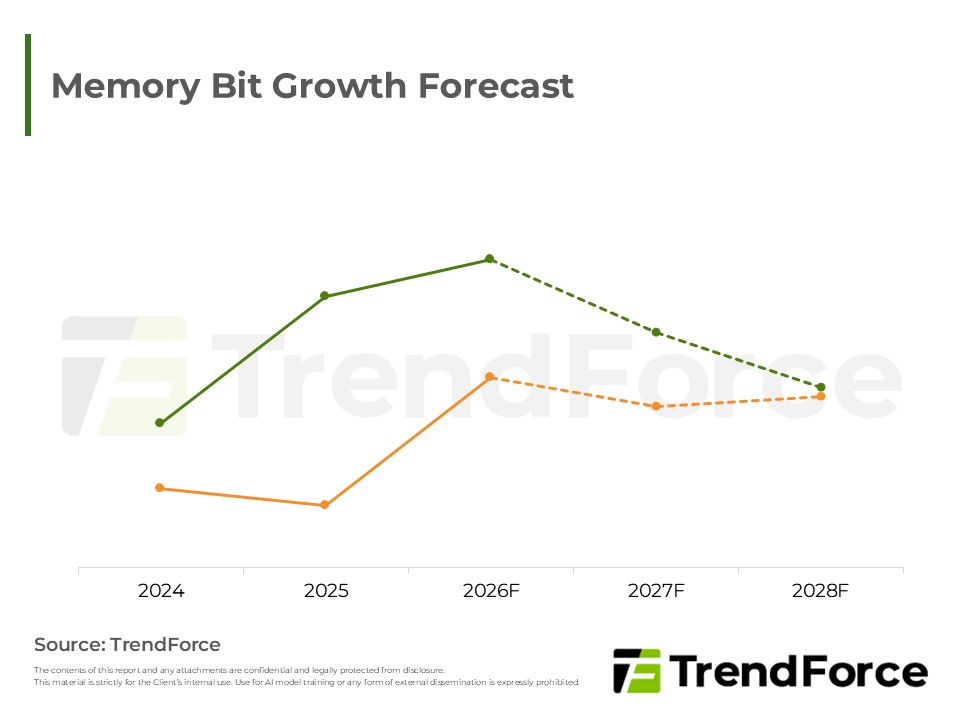
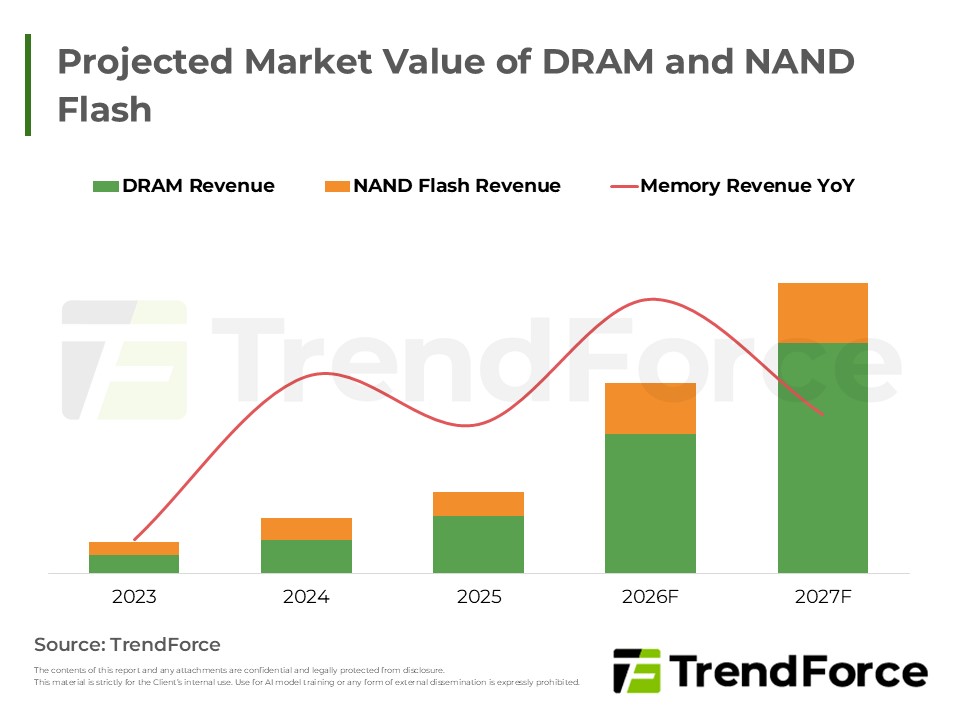
- Memory Expansion: Relieving cache pressure maximizes current resource efficiency. This sustains basic high-bandwidth memory needs while driving massive capacity upgrades for dynamic random-access memory and flash memory as computational extension layers.
Table of Contents
- TurboQuant Breaks Free from Bottlenecks of KV Cache, Surges in Efficiency of AI Inference, and Prompts Expansion of Long-Term Demand for Memory
- Management Optimization and Dimensionality Reduction in Content to Potentially Become Standard Configurations for Coordinated Designs of Software and Hardware
- Demand Structure of Memory Continues to Enlarge as Pressure on KV Cache Soothes
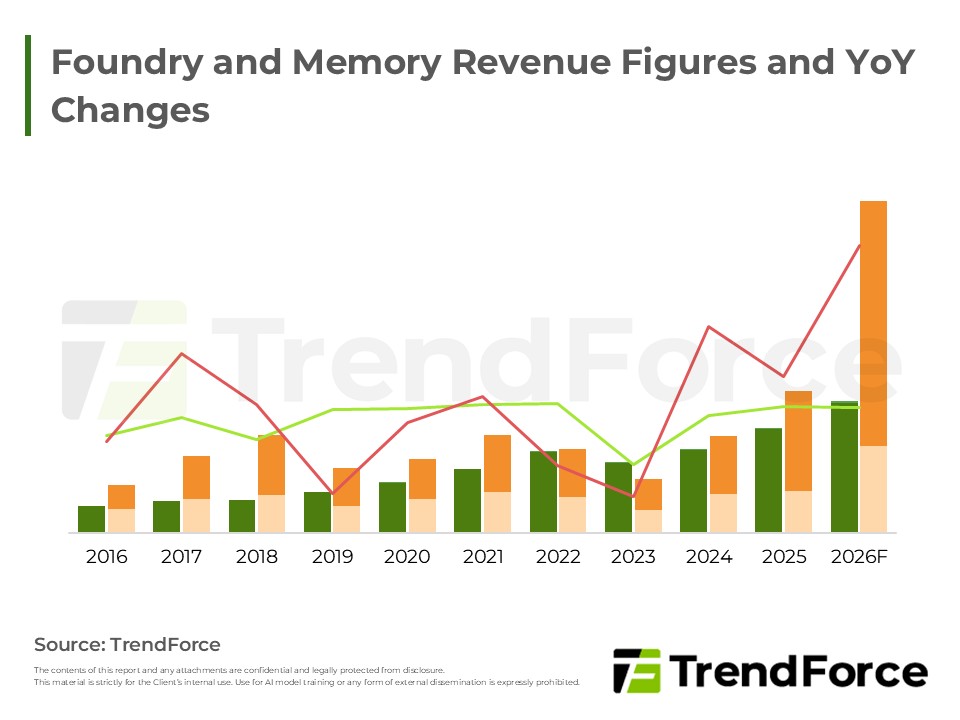
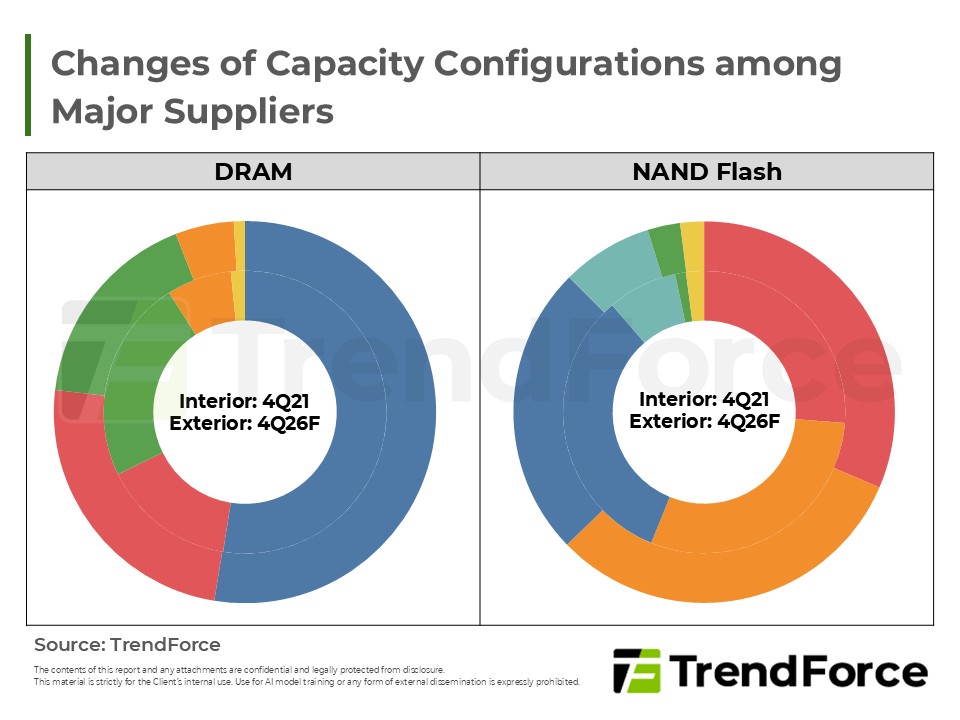
- Roles of DRAM and NAND Flash Continue to Evolve, from Main System Memory to Compute Extension Layers
- Share of Server-Related Memory and HBM in Overall Memory Demand
<Total Pages: 6>
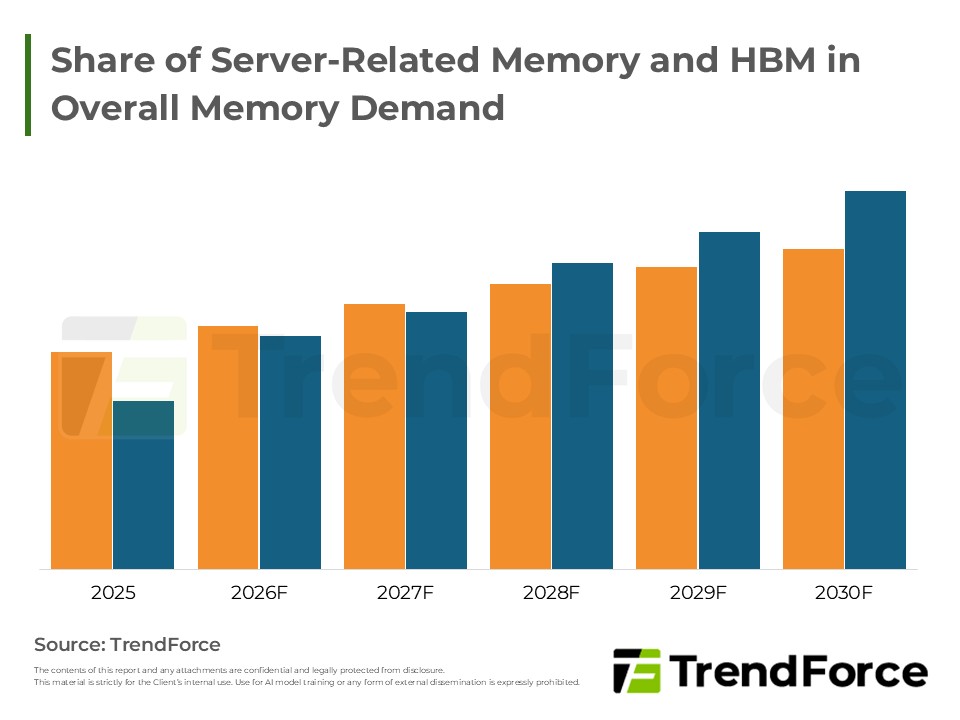
Category: DRAM , NAND Flash , AI/HBM/Server
Spotlight Report
-

DRAM Monthly Datasheet Jun. 2026

2026/06/16
Semiconductors

EXCEL
-

NAND Flash Monthly Datasheet Jun. 2026
2026/06/16
Semiconductors
PDF
-

2Q26 Memory Price Forecast
2026/03/26
Semiconductors
PDF
-

DRAM Contract Price May 2026
2026/05/29
Semiconductors
PDF
-

DRAM Contract Price Apr. 2026
2026/04/30
Semiconductors
PDF
-

DRAM Contract Price Mar. 2026
2026/03/31
Semiconductors
PDF
Memory PlatinumRelated Reports

Download Report
30,000
Membership
Spotlight Report
-
DRAM Monthly Datasheet Jun. 2026
2026/06/16
Semiconductors
EXCEL
-
NAND Flash Monthly Datasheet Jun. 2026
2026/06/16
Semiconductors
PDF
-
2Q26 Memory Price Forecast
2026/03/26
Semiconductors
PDF
-
DRAM Contract Price May 2026
2026/05/29
Semiconductors
PDF
-
DRAM Contract Price Apr. 2026
2026/04/30
Semiconductors
PDF
-
DRAM Contract Price Mar. 2026
2026/03/31
Semiconductors
PDF